S01 · Dashboard
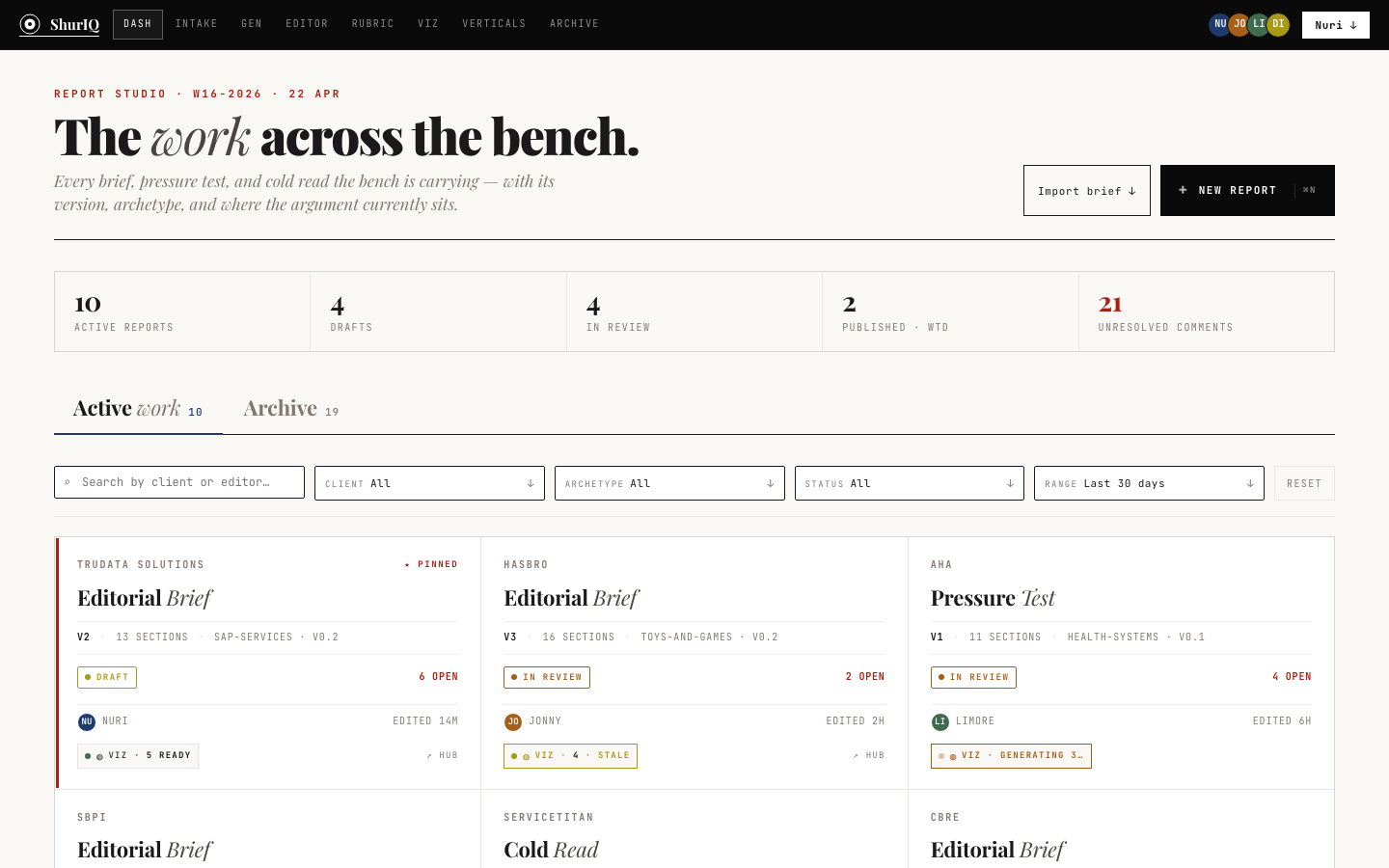
The work across the bench.
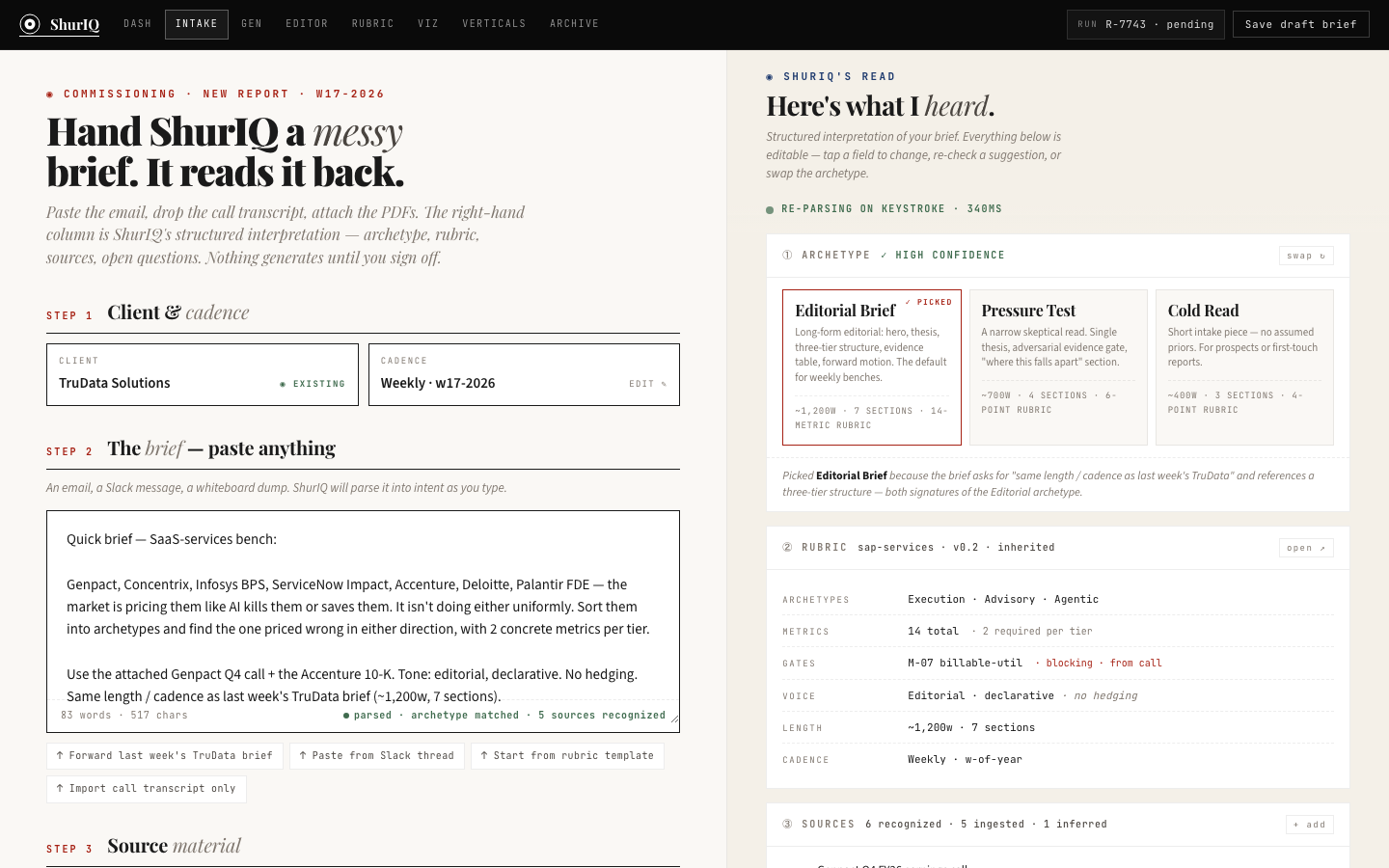
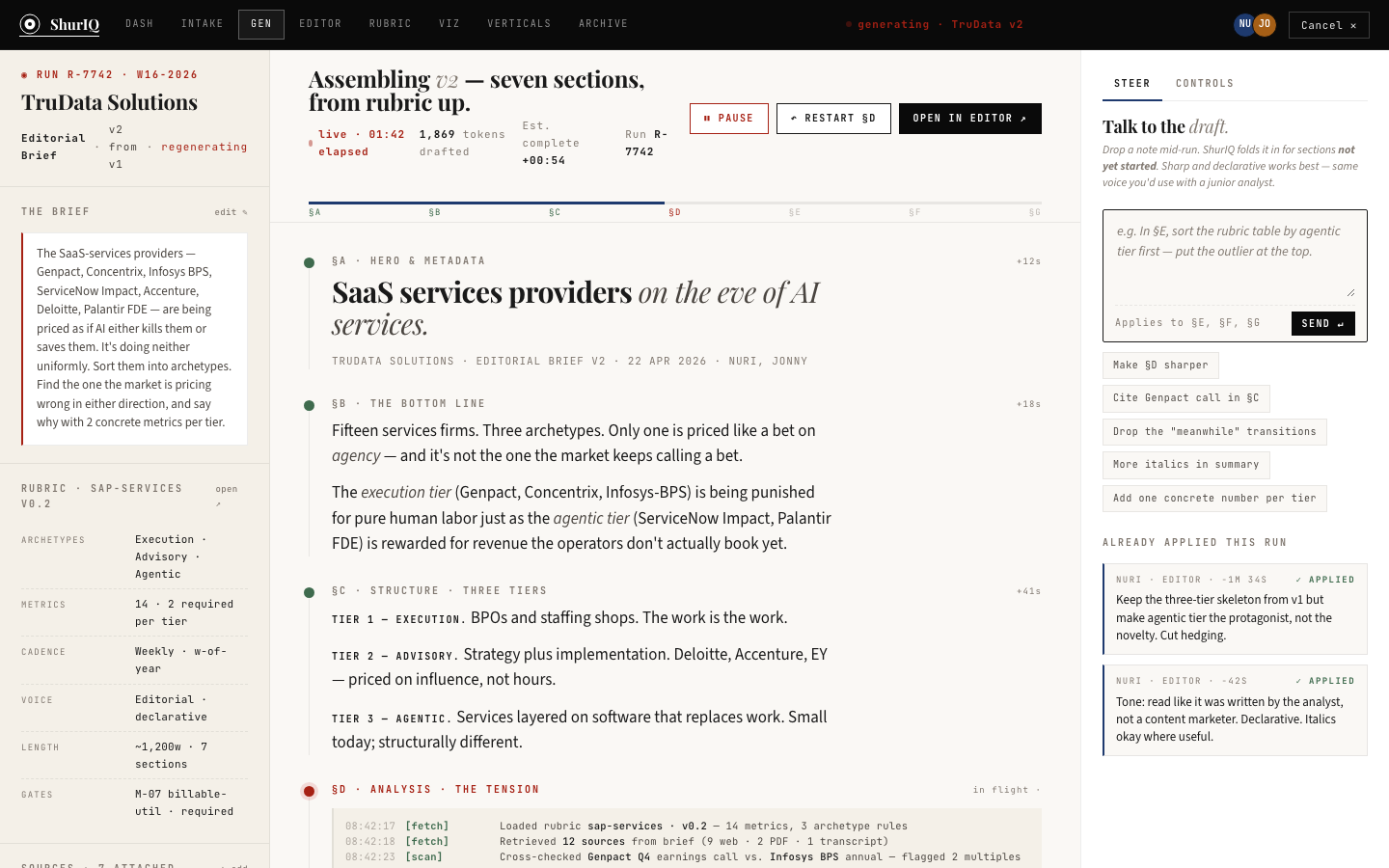
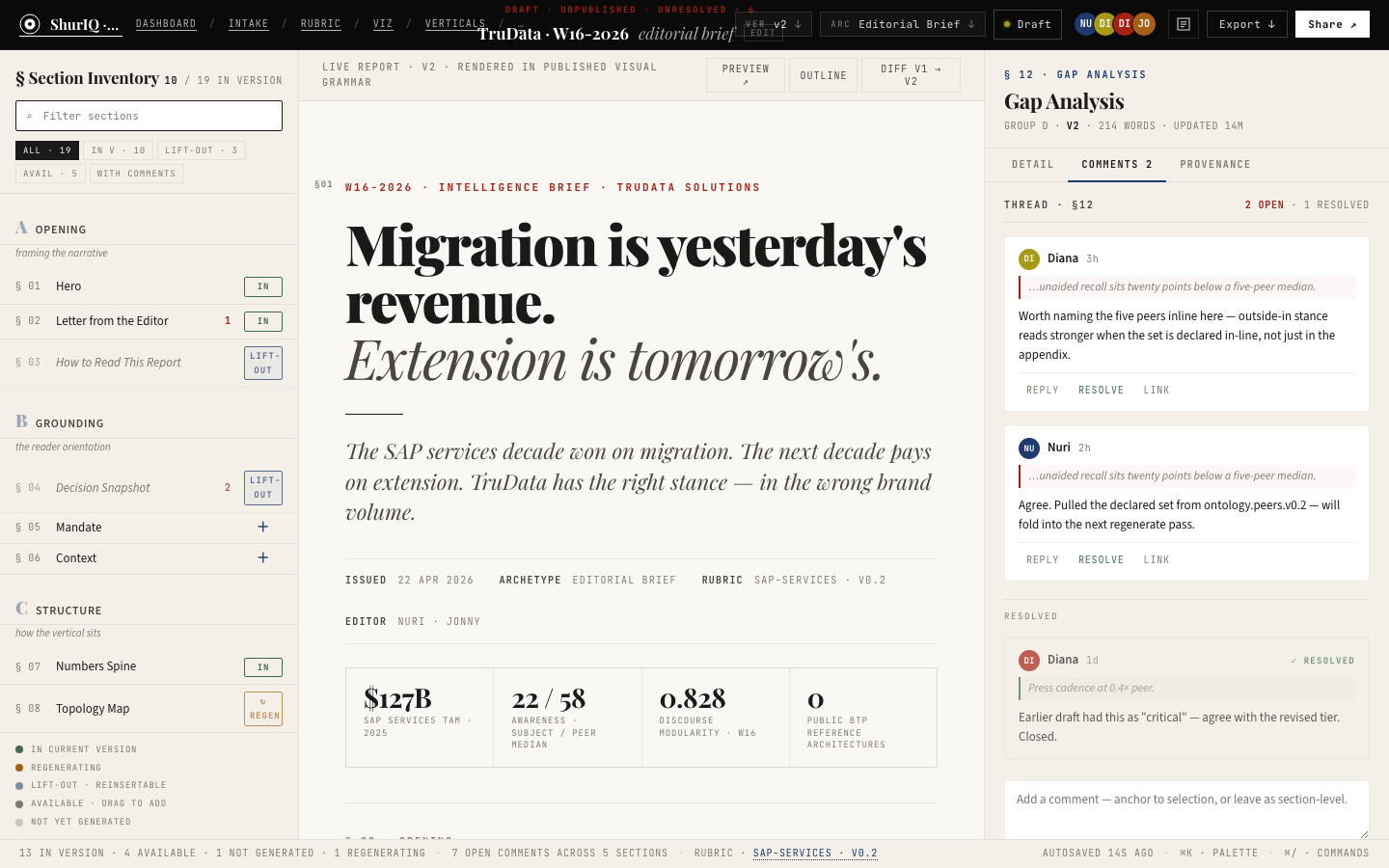
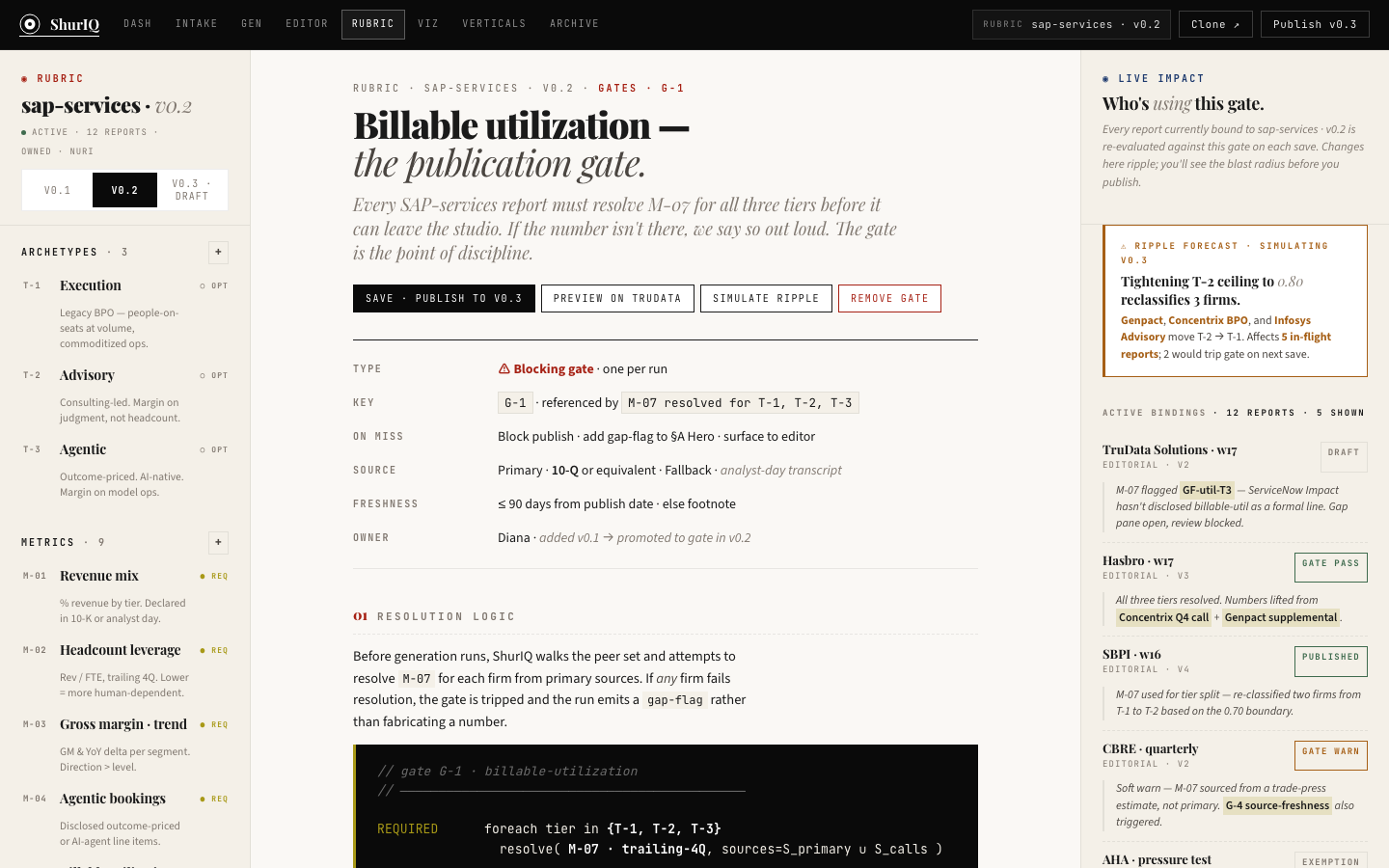
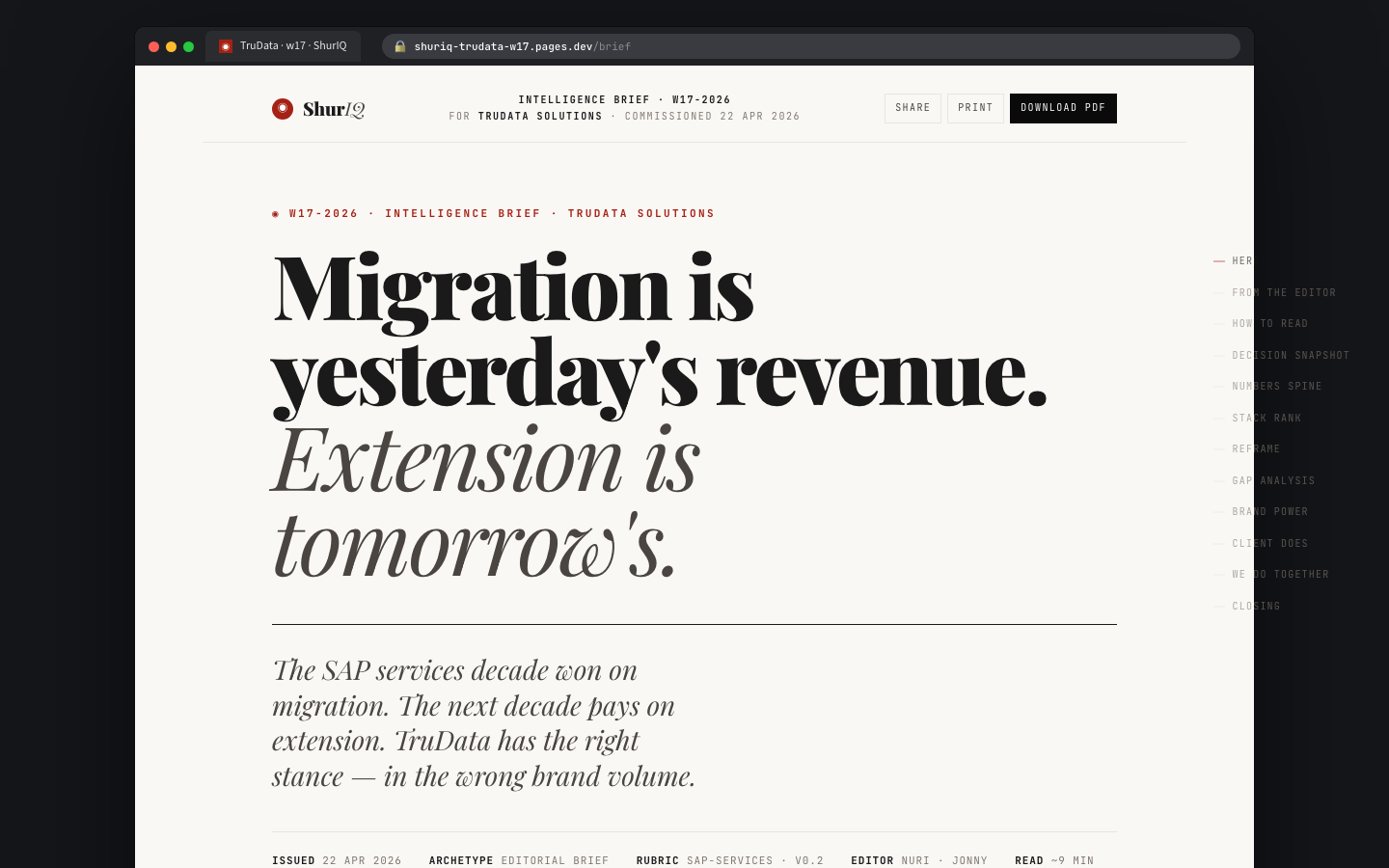
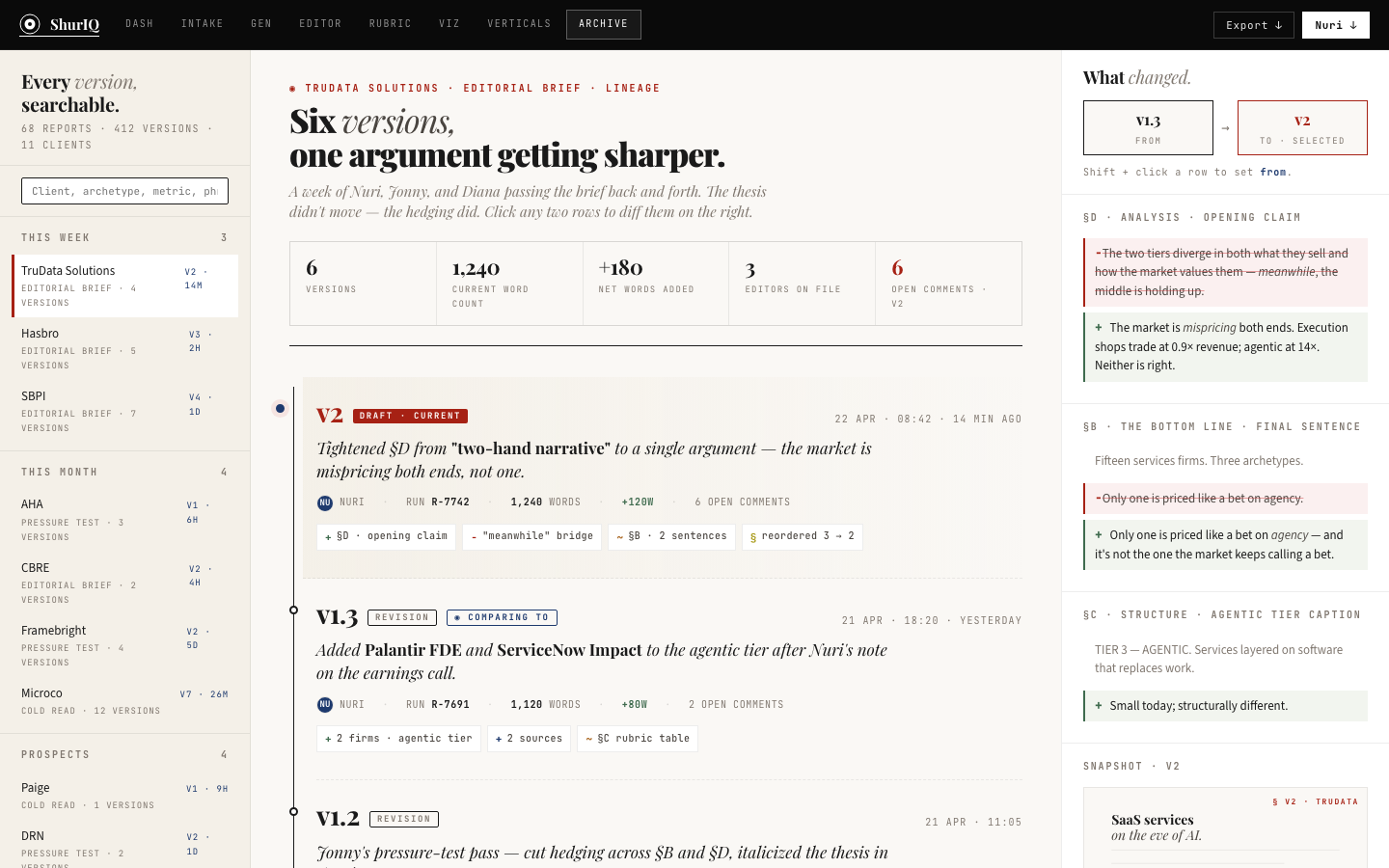
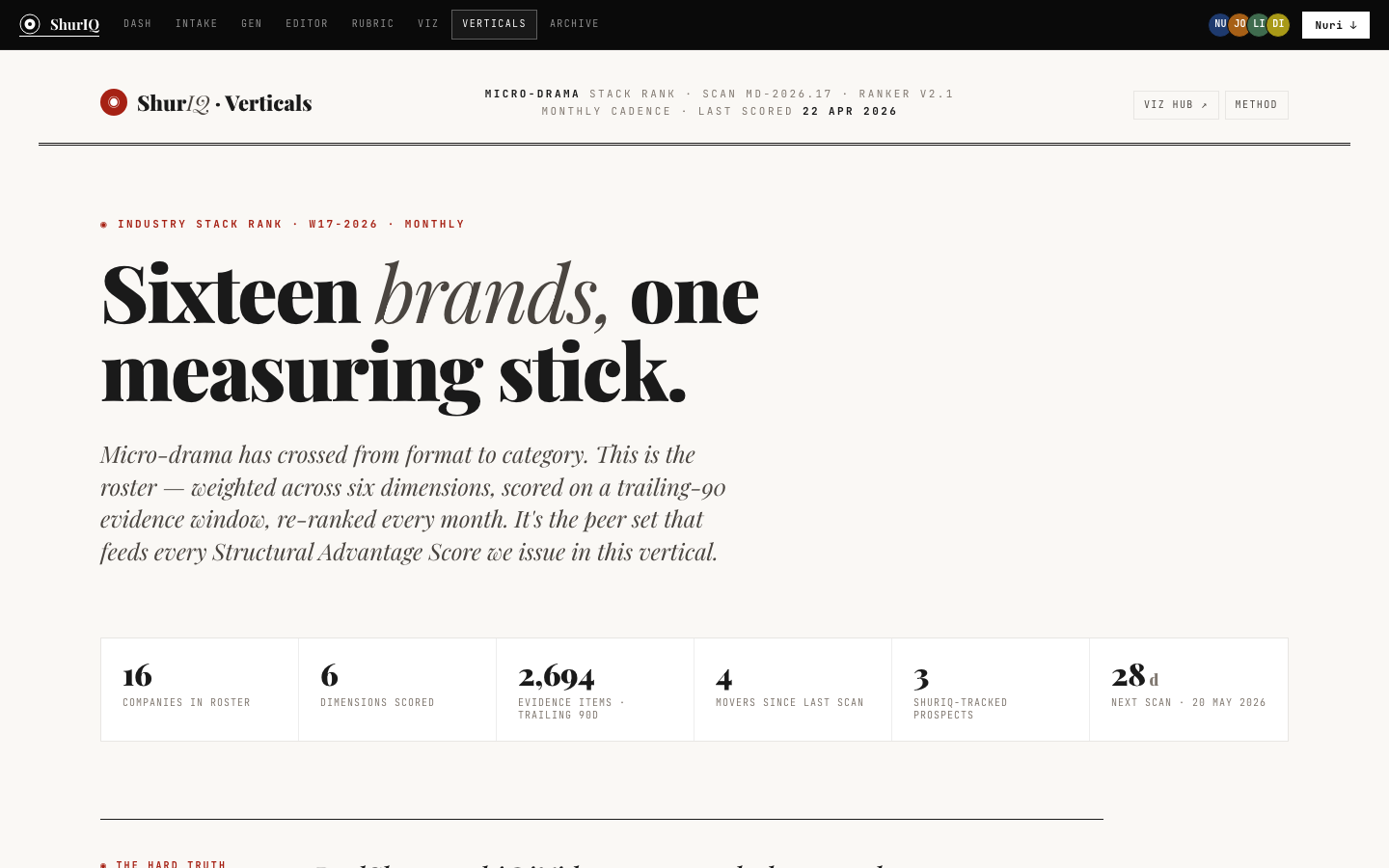
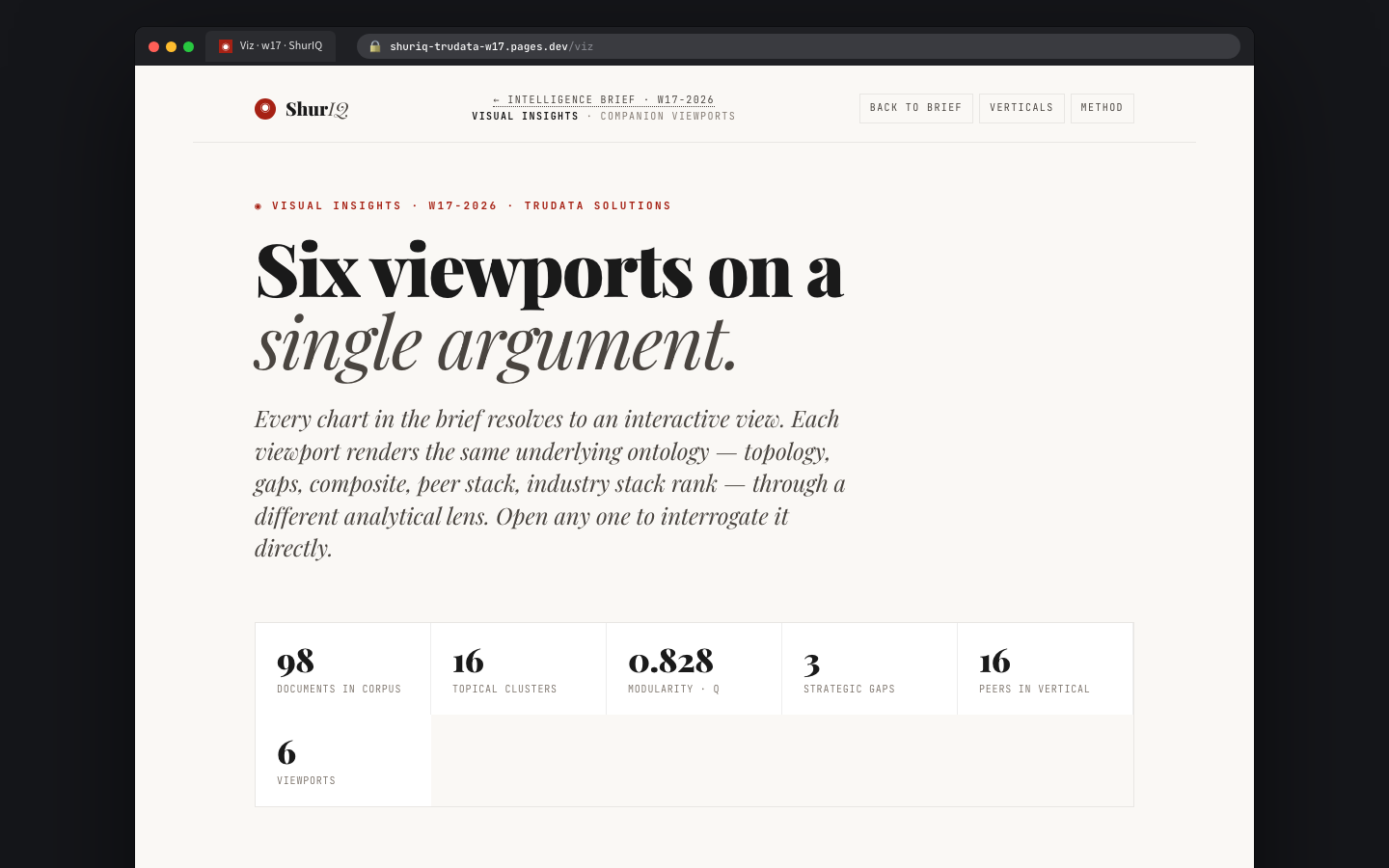
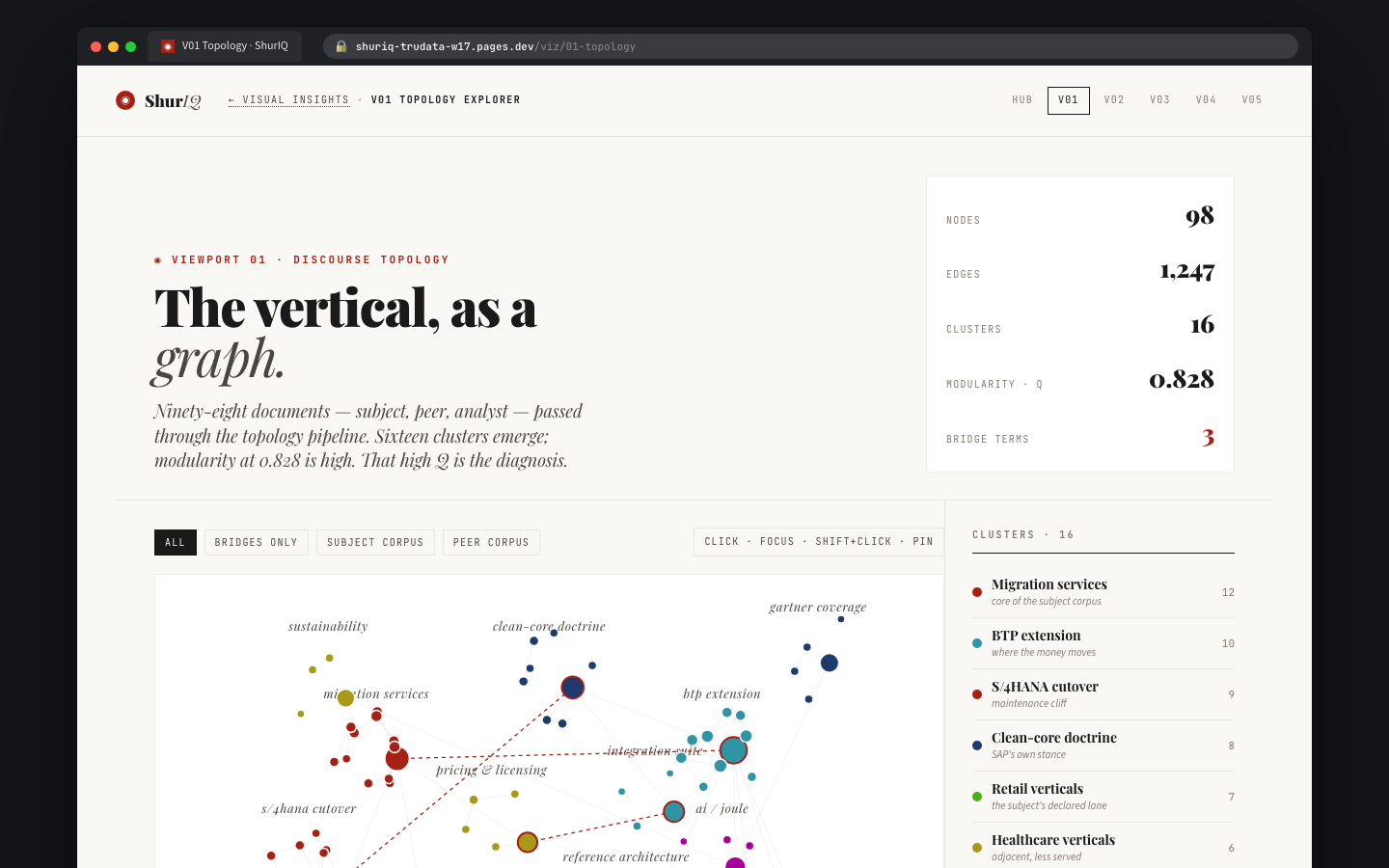
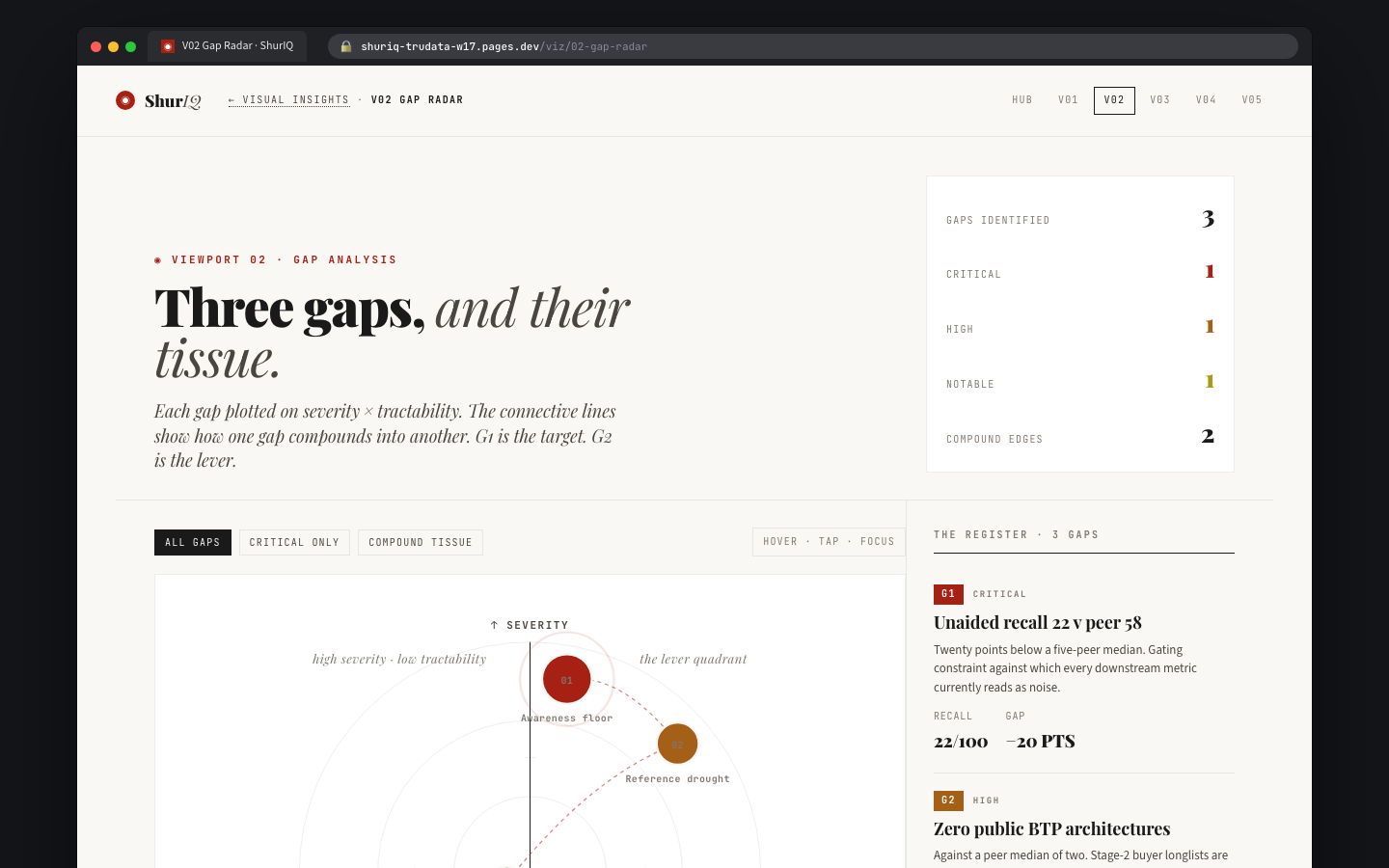
BuiltThe landing surface. Every active report — brief, pressure test, cold read — shows up as a card with client, version, archetype, status, rubric binding, and where the viz pipeline currently sits. Five-stat strip up top: active reports, drafts, in review, published-week-to-date, unresolved comments.
Filters by client, archetype, status, editor, and date range. The "pinned" pilot stays visible. One primary CTA — New Report — kicks off intake.